这篇笔记介绍CVPR2019的一篇基于attention的 style transfer文章:“Arbitrary Style Transfer with Style-Attentional Networks”。这篇文章没有采用AdaIN中替换均值和方差的方式,而是采用了attention的方式将content中的特征替换为style中的特征,从而实现风格的迁移。
SA module
首先介绍本文的核心创新点,style-attention module,可以看出,这个模块就是一个非常常见的Attention Module,其中Query 为 content feature,Key 和Value则为style feature。所以本质上这个attention的作用就是对于content feature map上的每个点,找到最合适的style feature map上的特征进行soft 替换。这个形式本质上和16年的style swap其实是一样的,但是这样的实现要高效许多。
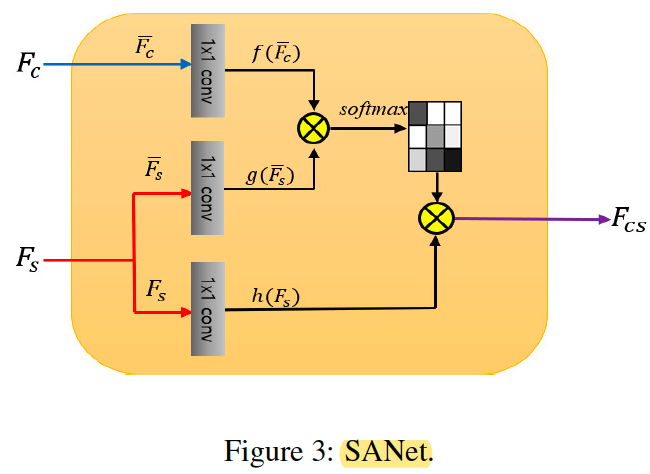
SANet
下面简单介绍一下网络整体的搭建方式。SANet 中采用了VGG encoder 中4-1 和5-1 这两层的特征,对content 和style 分别进行特征提取后,通过SA module 进行特征替换,之后求和并通过一个decoder进行重建。其中,SA module 和 decoder 是可学习部分。
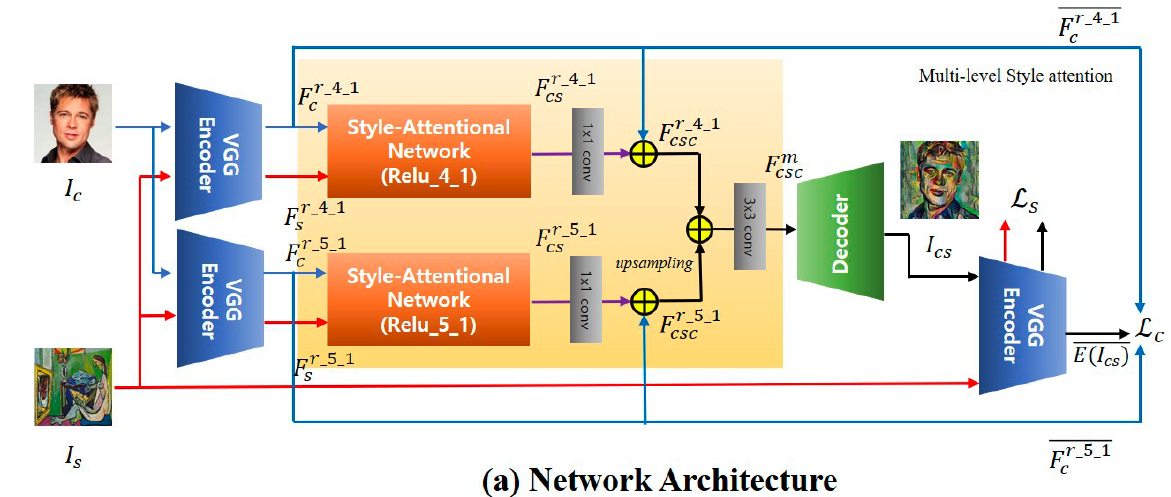
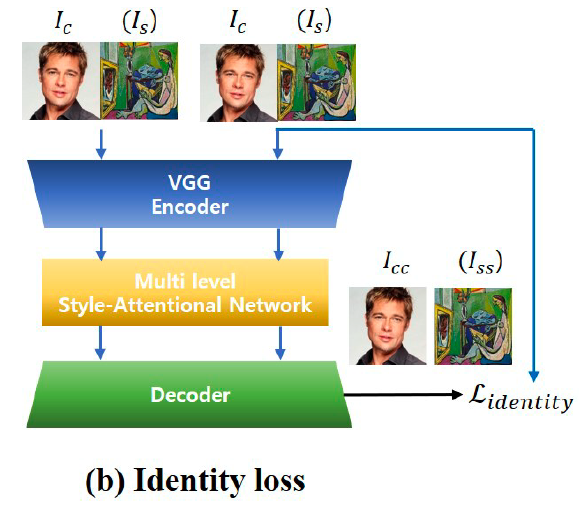
训练中,本文采用了和AdaIN中一样的content 和style loss,这里不再赘述。此外,本文还采用了一种identity loss,即在SA module 中,content 或者style image 和自身进行特征交换的话,结果应当是重建原图的效果。
实验
SANet 的效果还是相当不错的,下面做一些展示。
多尺度特征实验
如下结果表明,越底层的feature,其生成结果的纹理更接近原图,而深层的特征,其结果则更加抽象,结合两个尺度能够获得更理想的效果。

风格迁移程度控制
SANet 中的风格迁移程度控制,是做SA(content,style) 和 SA(content, content) 之间的加权平均,而不能直接和content feature 做平均。这应该是因为训练identity loss的时候,同样也使用了SA module。

多风格混合

空间控制

小结
- SANet 很简单有效地将attention引入了style transfer任务中(万能的attention。。)
- SANet 中存在的一个问题是,attention 的过程中可能会引入噪声,相邻点之间的attention 可能存在噪声。对于图片而言问题不大,但是要对视频做风格化时抖动就会非常的厉害。当然,光流可以在很大程度上优化这个问题,但若想从网络本身入手,则需要多SANet 的模块本身进行一定的优化。
- 优化的方式,或许可以考虑对attention 做一个平滑,使得相邻点的attention 尽可能相似