前两天德国基尔大学的研究者在arXiv上上传了一篇关于半监督/自监督/无监督图像分类技术的调研文章。对相关的概念有比较清楚的介绍,这里做一些简单的翻译和笔记。
深度学习近几年在图像领域获得了很大的成功,但常常依赖于大量有标注的数据。然而,在很多实际的问题和应用当中,获取大量有标签的训练数据是很困难或是很昂贵的。因此,使用更少的标签来训练网络来达到同等的效果就很重要。与之相关的研究领域,包括半监督学习、自监督学习和无监督学习等,是这两年各个任务上的研究重点。这些领域的重点都在于如何去更好地利用无标签数据来提升模型效果,文中给了下图来说明为何无标签数据能够做到这一点。
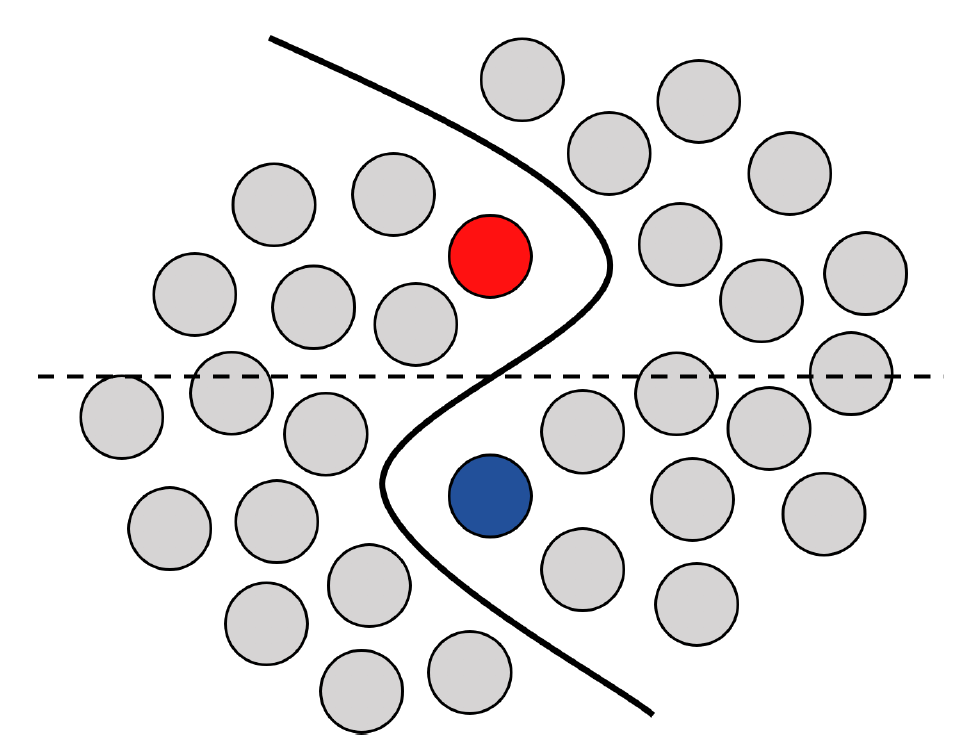
如图所示,红色和蓝色的点代表了有标签数据,灰色点代表了无标签数据。如果只有有标签数据,模型得到的分类面将是虚线,而在无标签数据的帮助下,模型能够学习到实线作为分类面,更加符合数据的真实分布。
因为论文非常多,所以文中主要比较了图像分类任务上常用的一些方法。此外,作者总结了三个研究趋势:
- SOTA的方法已经能够扩展到真实的应用中;
- 达到相近性能的结果所需要使用的标签数量在不断下降;
- 所有的方法都共享了一些常见的技术,但是只有很少的方法能够将技术结合起来获得更好的效果;
第三点挺有意思,武器库中的武器大家都能用,但是如何合理的组合并发挥好的效果还是很难的一件事情。
基本概念
学习策略
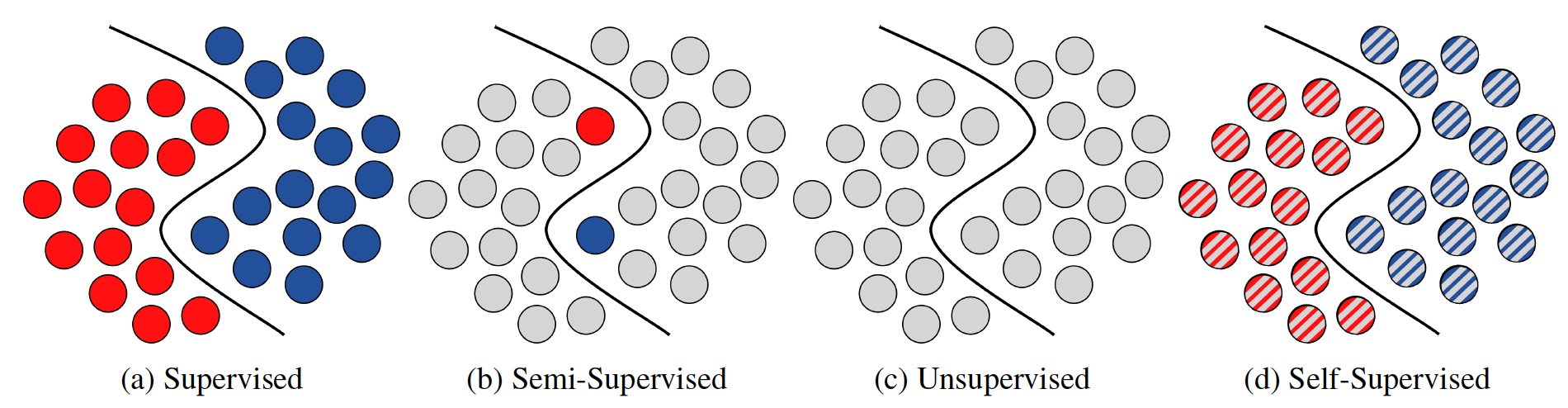
监督学习
无监督学习
半监督学习
自监督学习
技术介绍
一致性正则化(Consistency regularization)
虚拟对抗训练(VAT)
互信息(MI)
熵最小化(EntMin)
均方误差(MSE)
过聚类(Overclustering)
伪标签(Pseudo-Labels)
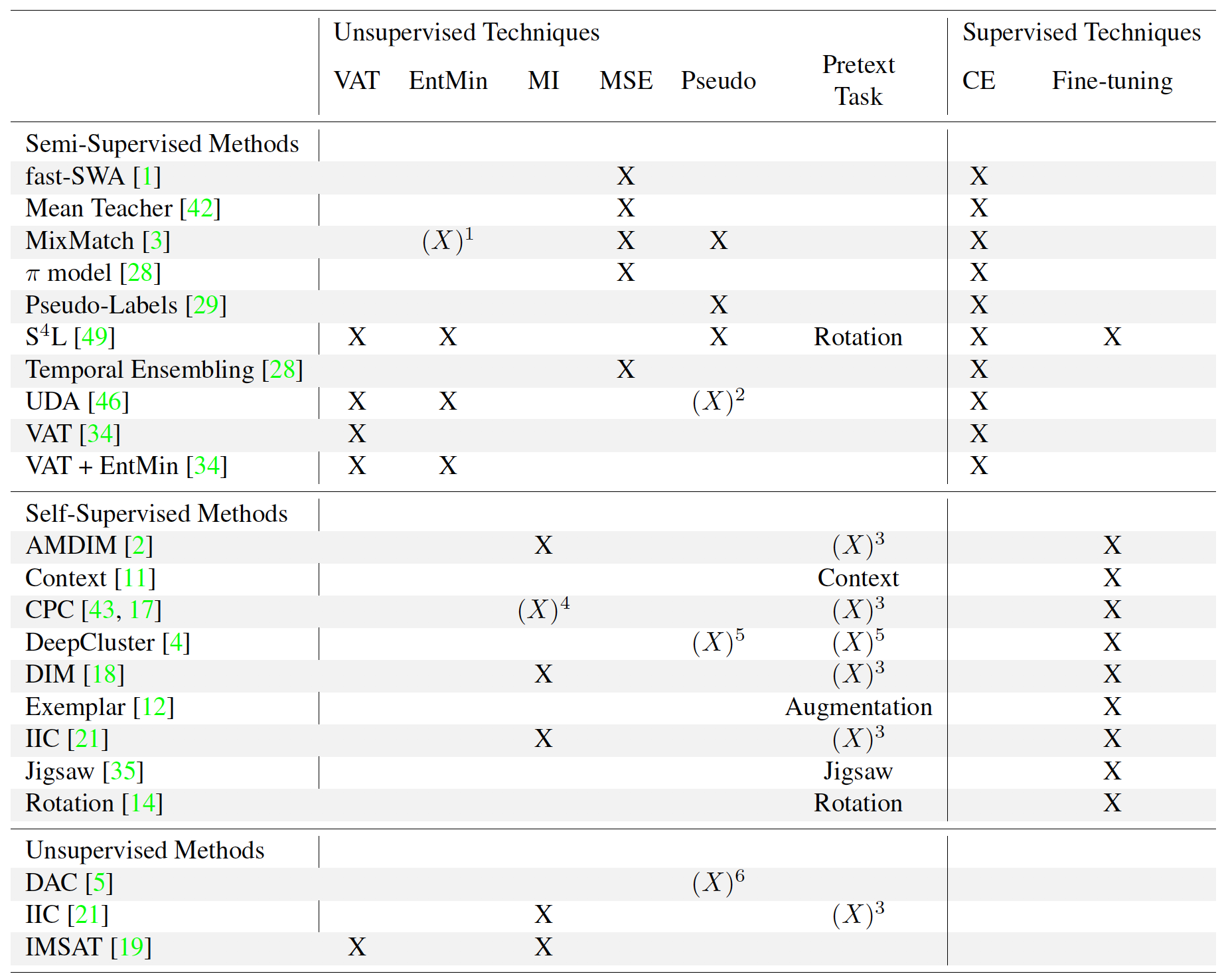
方法介绍
半监督学习
Fast-Stochastic Weight Averaging (fast-SWA)
Mean Teacher
MixMatch
$\pi$-model and Temporal Ensembling
Pseudo-Labels
Self-Supervised Semi-Supervised Learning (S4L)
Unsupervised Data Augmentation (UDA)
Virtual Adversarial Training (VAT)
自监督学习
Augmented Multiscale Deep InfoMax (AMDIM)
Contrastive Predictive Coding (CPC)
DeepCluster
Deep InfoMax (DIM)
Invariant Information Clustering (IIC)
Representation Learning - Context
Representation Learning - Exemplar
Representation Learning - Jigsaw
Representation Learning - Rotation
无监督学习
Deep Adaptive Image Clustering (DAC)
Invariant Information Clustering (IIC)
Information Maximizing Self-Augmented Training (IMSAT)
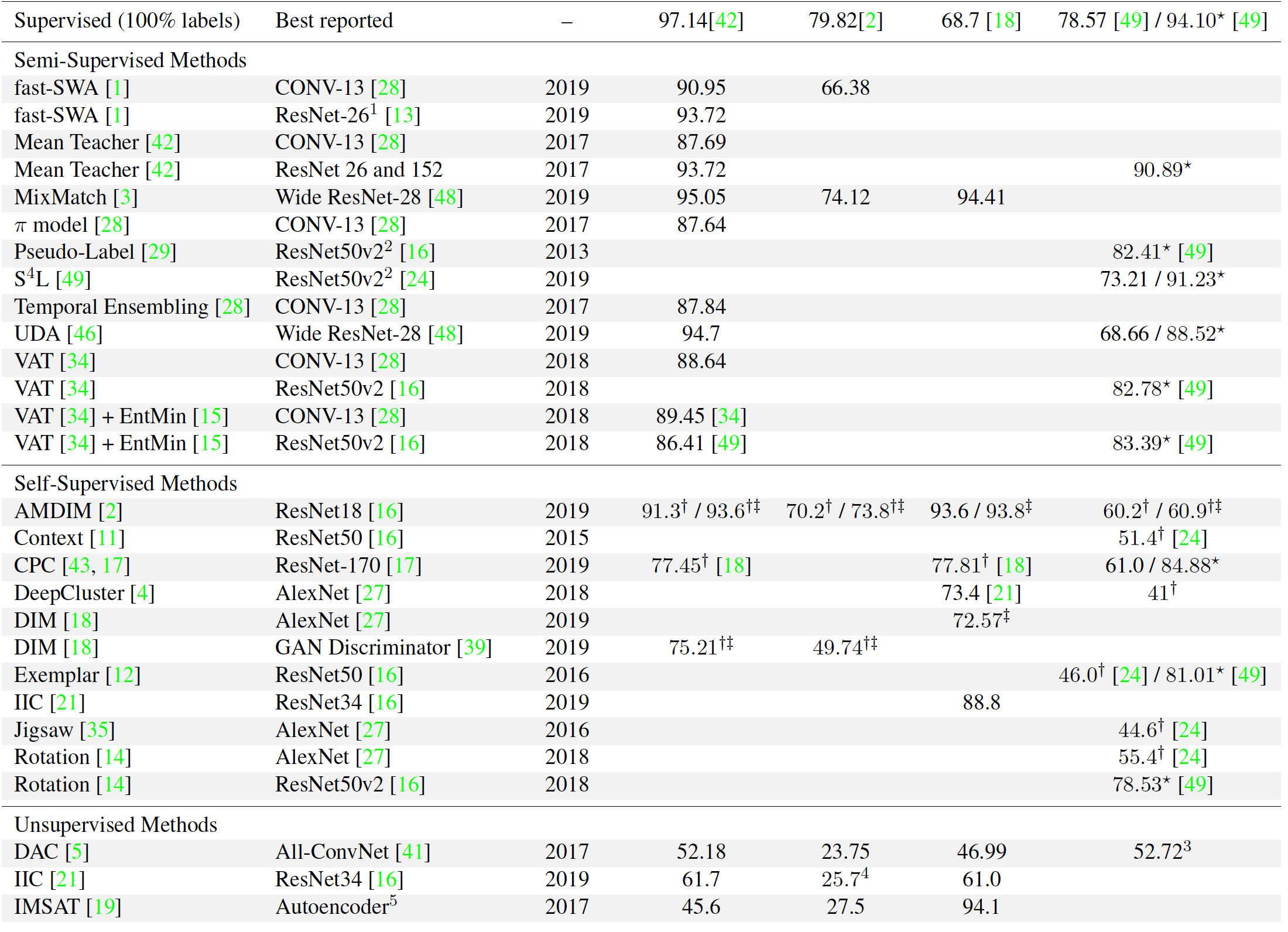
方法比较
实验比较